書き起こしを開始する
mocoVoiceの書き起こし機能を利用するには、以下の手順で行ってください。
APIキーの作成
サイドメニューから「APIキー」を選択し、APIキー管理画面を開きます。 「APIキーを作成」を選択し、APIキーの名前を入力して作成します。

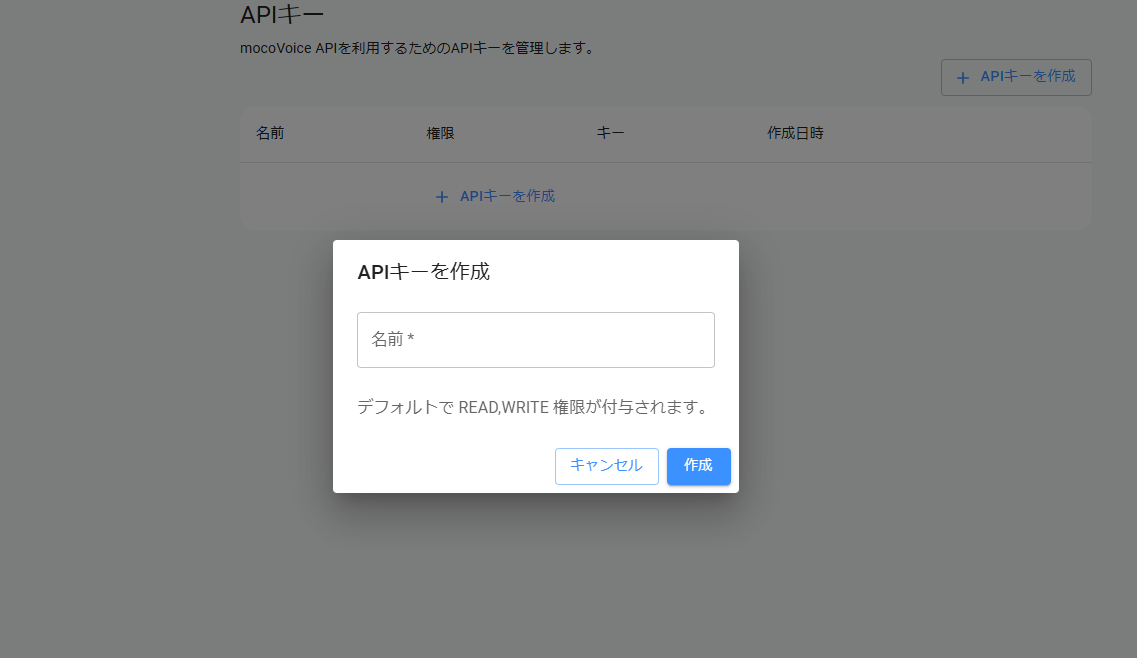
キーが生成されたら、クリップボードにコピーしてください。
音声ファイルのアップロード
音声ファイルをアップロードするには、以下の手順を実行します。
- 音声認識ジョブを作成する
- アップロード用URLにファイルをアップロードする
1. 音声認識ジョブを作成する
ジョブ作成APIリクエストとして、音声ファイルのURLを指定し、mocoVoice非同期HTTPインターフェースのエンドポイントにリクエストを送信します。
POST https://cloud.mocomoco.ai/api/v1/transcriptions/upload
例えば、curlコマンドで test.wav の音声認識リクエストを送信するには、以下のようにします。
curl -X 'POST' \
'https://api.mocomoco.ai/api/v1/transcriptions/upload' \
-H 'accept: application/json' \
-H 'X-API-KEY: {API_KEY}' \
-H 'Content-Type: application/json' \
-d '{
"filename": "test.wav",
"language": "ja"
}'※一度作成したジョブは、1回のみ音声認識リクエストが可能です。新しい音声ファイルに対して音声認識リクエストを送る場合は、新しいジョブを作成してくだい。
オプションの説明
HTTPリクエストで使用するオプションは以下の通りです。
| パラメータ名 | 型 | 必須 | 説明 |
|---|---|---|---|
filename | string | 必須 | アップロードする音声ファイルの名前 |
language | string or array<string> | 任意 | 音声ファイルの言語コード('en'、'ja', 'ko'など)または言語コードの配列(['ja', 'en']) |
対応言語のISO 639-1コードを入力することで言語を指定できます。
成功した場合
成功時のレスポンスには transcription_id が含まれます。 これは、音声認識リクエストに対するジョブのIDで、ジョブの状態確認や結果取得に利用します。 audio_upload_url には、音声をアップロードできるURLが含まれます。
{
"transcription_id": "string",
"dictionary_id": "string",
"team_id": "string",
"name": "string",
"transcription_path": "string",
"audio_path": "string",
"status": "PENDING",
"speaking_duration": 0,
"created_at": "2024-10-03T01:10:15.403Z",
"updated_at": "2024-10-03T01:10:15.403Z",
"audio_upload_url": "https://mocovoice..."
}2. アップロード用URLにファイルをアップロードする
audio_upload_url にファイルをアップロードします。認証情報はURLに含まれているため、この段階でAPIキーは不要です。
curl -X 'PUT'\
'{audio_upload_url}'\
-H 'Content-Type: audio/wav' \
--upload-file test.wavContent-Typeは、ファイルに合わせて設定します。例ではaudio/wavを設定しましたが、mp3の場合は、audio/mpegを設定してください。
書き起こしジョブの実行
ファイルがアップロードされたら、手順1で取得した transcription_id を用いて書き起こしを実行します。 ここでは、transcription_id が xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx であるとします。
curl -X 'POST' \
'https://api.mocomoco.ai/api/v1/transcriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/transcribe' \
-H 'accept: application/json' \
-H 'X-API-KEY: {API_KEY}' \
-d ''レスポンス例:
{
"transcription_id": "string",
"dictionary_id": "string",
"team_id": "string",
"name": "string",
"transcription_path": "string",
"audio_path": "string",
"status": "IN_PROGRESS",
"speaking_duration": 0,
"created_at": "2024-10-03T01:15:02.975Z",
"updated_at": "2024-10-03T01:15:02.975Z",
"audio_upload_url": "null"
}音声認識ジョブの状態を確認する
音声認識ジョブ作成リクエストが成功したら、ジョブの状態を確認します。status が completed または error になるまで定期的に確認(ポーリング)してください。
ジョブの状態取得
ジョブはサーバー側で順次実行されます。 状態の確認や結果の取得には、結果取得用エンドポイント GET /v1/transcriptions/{transcription_id} に問い合わせます。
transcription_id には、ジョブ作成時に取得したジョブIDを設定します。 リクエストパラメータの認証情報として、X-API-KEY ヘッダーにAPIキーを指定してください。
curlで実行する場合は以下のようになります。 ここでは、transcription_id が xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx であるとします。
curl -X 'GET' \
'https://api.mocomoco.ai/api/v1/transcriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx' \
-H 'accept: application/json' \
-H 'X-API-KEY: {API_KEY}'PENDING状態
アップロードリクエスト直後は、status は PENDING 状態です。
{
"transcription_id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"dictionary_id": "string",
"team_id": "string",
"name": "string",
"transcription_path": "string",
"audio_path": "string",
"status": "PENDING",
"speaking_duration": 0,
"created_at": "2024-10-03T01:15:02.975Z",
"updated_at": "2024-10-03T01:15:02.975Z",
"audio_upload_url": "string"
}IN_PROGRESS状態
実際に音声認識処理が開始されると、status は IN_PROGRESS 状態に変わります。
{
"transcription_id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"dictionary_id": "string",
"team_id": "string",
"name": "string",
"transcription_path": "string",
"audio_path": "string",
"status": "IN_PROGRESS",
"speaking_duration": 0,
"created_at": "2024-10-03T01:15:02.975Z",
"updated_at": "2024-10-03T01:15:02.975Z",
"audio_upload_url": "string"
}IN_PROGRESS から次の COMPLETED 状態になるまでの時間は、音声の長さに依存しますが、通常は音声の長さの0.2〜0.8倍程度です。 mocoVoiceは高速処理を特長としており、これより短い時間で処理が完了する場合があります。
COMPLETED状態
音声認識が完了すると、status は COMPLETED 状態になります。 この時、レスポンスの transcription_path で指定された場所から音声認識結果を取得できます。 結果は、音声認識サーバーでの処理完了後、一定期間保存されます。
{
"transcription_id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"dictionary_id": "string",
"team_id": "string",
"name": "string",
"transcription_path": "string",
"audio_path": "string",
"status": "COMPLETED",
"speaking_duration": 33.5,
"created_at": "2024-10-03T01:15:02.975Z",
"updated_at": "2024-10-03T01:15:02.975Z",
"audio_upload_url": "string"
}FAILED状態
何らかの理由で音声認識に失敗した場合、status は FAILED 状態になります。
{
"transcription_id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"dictionary_id": "string",
"team_id": "string",
"name": "string",
"transcription_path": "string",
"audio_path": "string",
"status": "FAILED",
"speaking_duration": 0,
"created_at": "2024-10-03T01:15:02.975Z",
"updated_at": "2024-10-03T01:15:02.975Z",
"audio_upload_url": "string"
}書き起こしデータの取得
ジョブの状態が completed になったら、レスポンスフィールドの transcription_path から書き起こしデータを取得できます。
curl -X 'GET' \
'{transcription_path}' \[
{"text": "string", "lang": "string", "start": number, "end": number, "speaker": "SPEAKER_00"},
{"text": "string", "lang": "string", "start": number, "end": number, "speaker": "SPEAKER_01"},
.
.
.
]より詳細な操作については、APIリファレンスをご確認ください。