書き起こしを開始する
mocoVoiceでは、Webブラウザ上で簡単に音声ファイルや動画ファイル、またはお使いのデバイスのマイクで録音した音声から書き起こしを開始できます。
書き起こしの準備
- mocoVoiceにログインします。
- 左側のサイドバーから「mocoVoice」を選択します。
音声入力方法の選択
書き起こしを行うには、まず音声ソースを指定する必要があります。以下のいずれかの方法で入力してください。
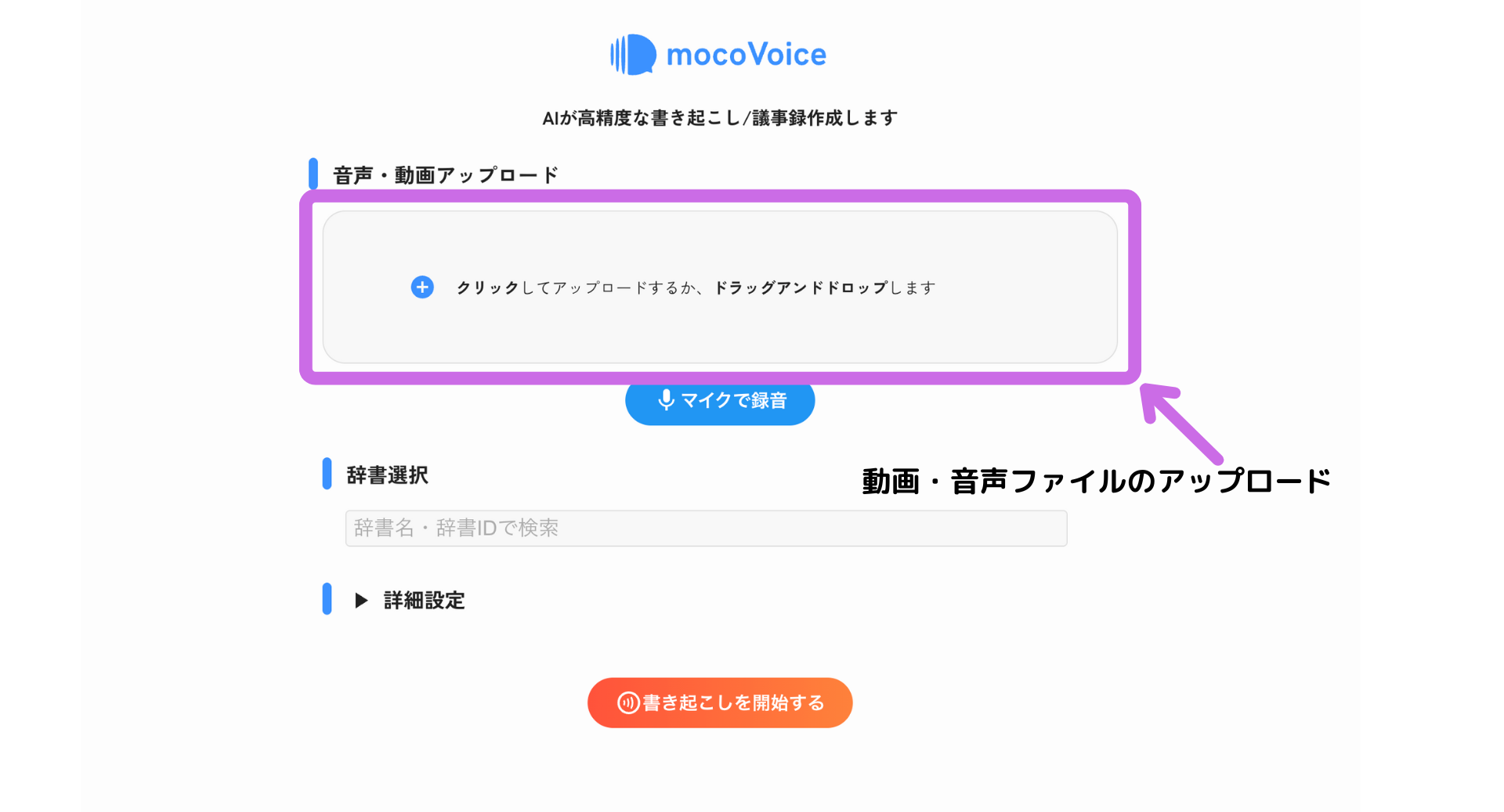
1. 音声・動画ファイルをアップロードする
お手持ちの音声ファイルや動画ファイルをアップロードして書き起こしを行います。
- ドラッグ&ドロップ: 画面中央の「音声・動画アップロード」エリアにファイルをドラッグ&ドロップします。
- クリックして選択: 「音声・動画アップロード」エリアをクリックし、ファイル選択ダイアログからファイルを選びます。
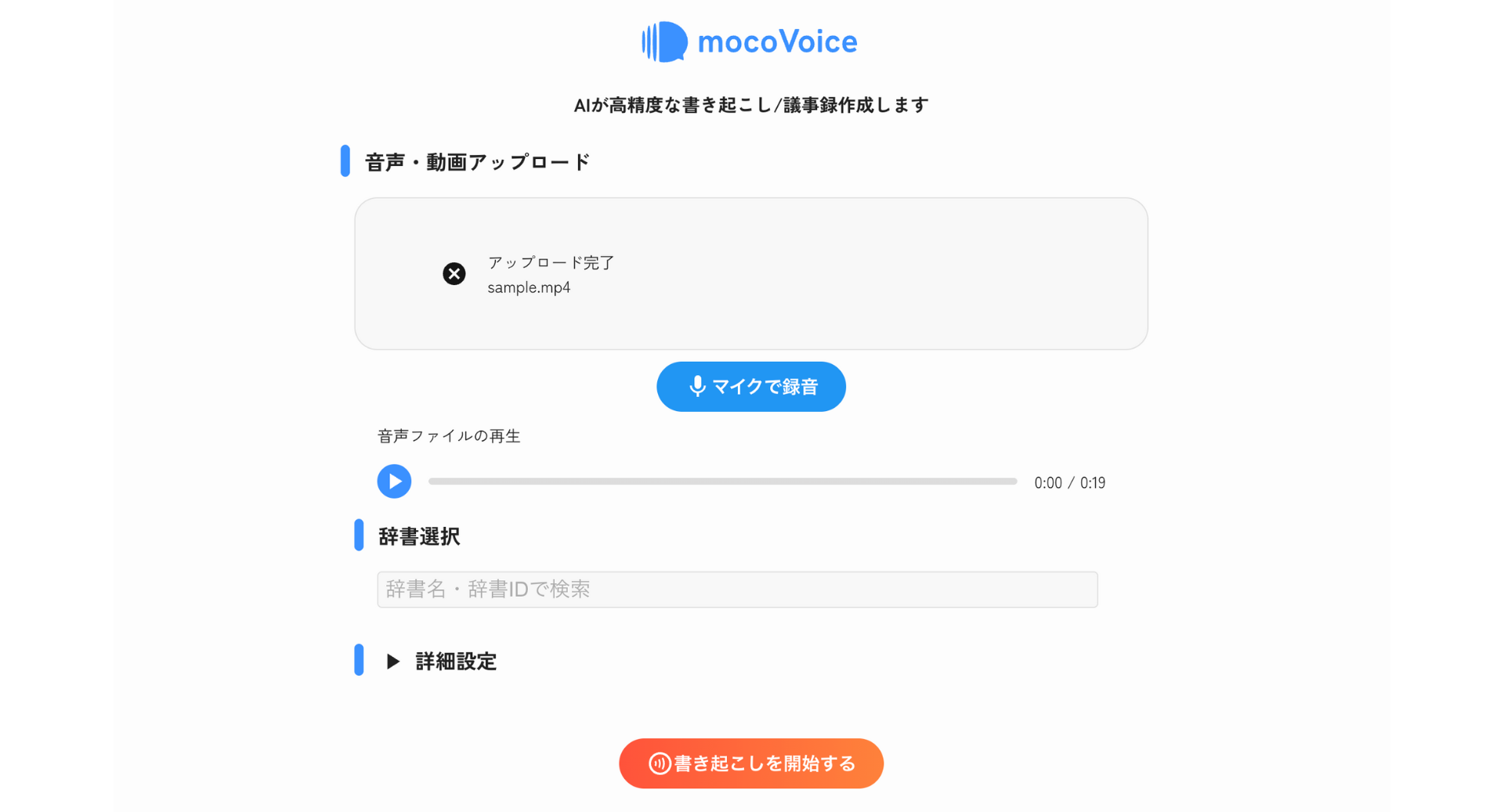
ファイルがアップロードされると、ファイル名が表示され、再生して内容を確認できます。
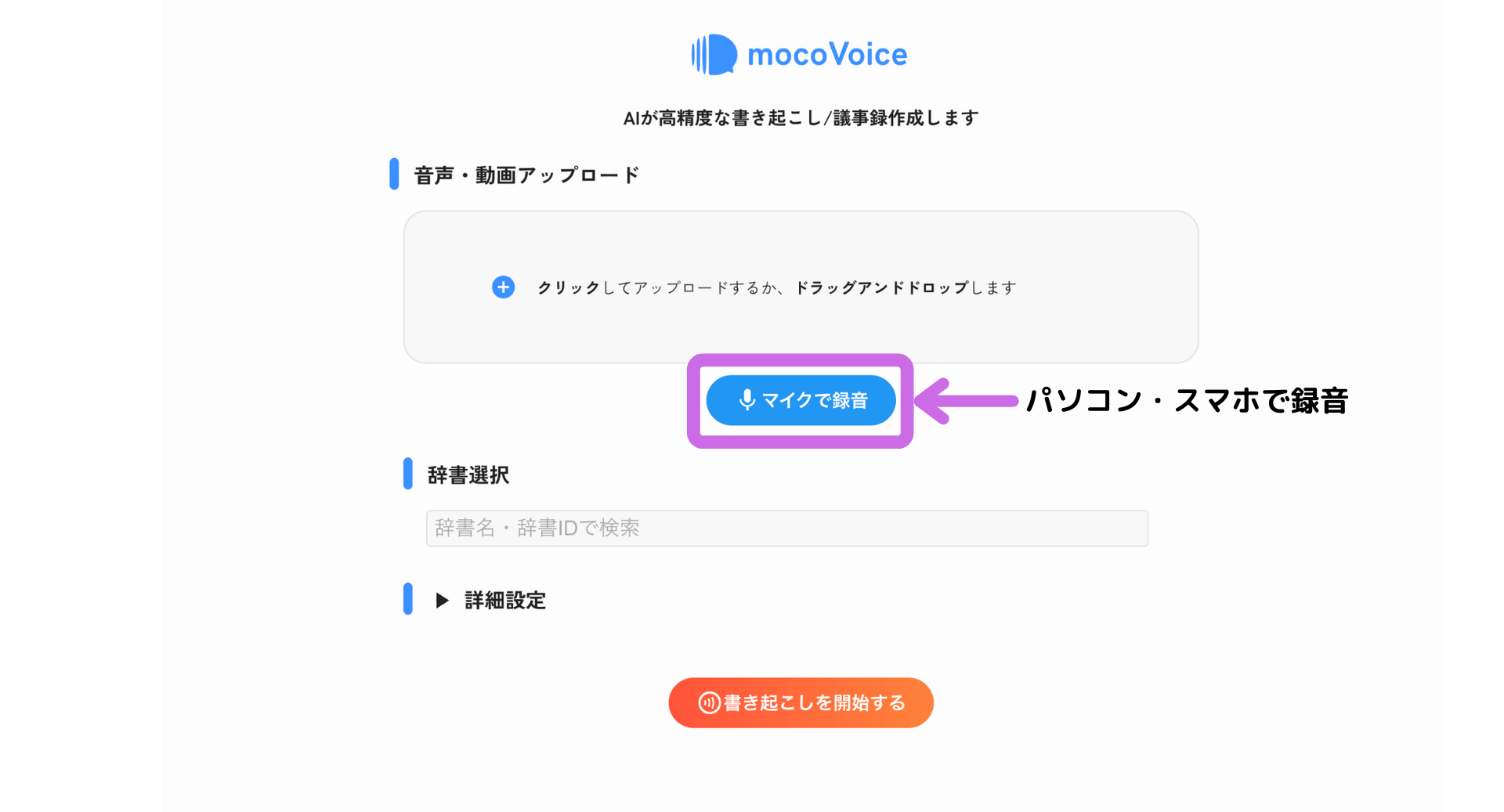
2. デバイスのマイクで録音する
お使いのパソコンやスマートフォンのマイクを使って音声を録音し、その音声データを書き起こしの対象とすることができます。
- 「マイクで録音」ボタンをクリックします。初めて利用する際には、ブラウザからマイクへのアクセス許可を求められますので、「許可」を選択してください。
- 録音画面が表示されます。録音ボタンをクリックして録音を開始し、完了したら停止ボタンをクリックします。
- 録音された音声データが自動的にアップロードされ、書き起こしの準備が整います。
オプションの設定(任意)
書き起こしを開始する前に、必要に応じて以下のオプションを設定できます。
辞書選択
特定の専門用語や固有名詞の認識精度を高めたい場合は、あらかじめ登録しておいた辞書を選択します。辞書の登録・利用方法については、辞書を使って精度を上げるをご覧ください。
詳細設定
「詳細設定」をクリックすると、書き起こしの品質や言語に関する設定を行えます。
品質設定
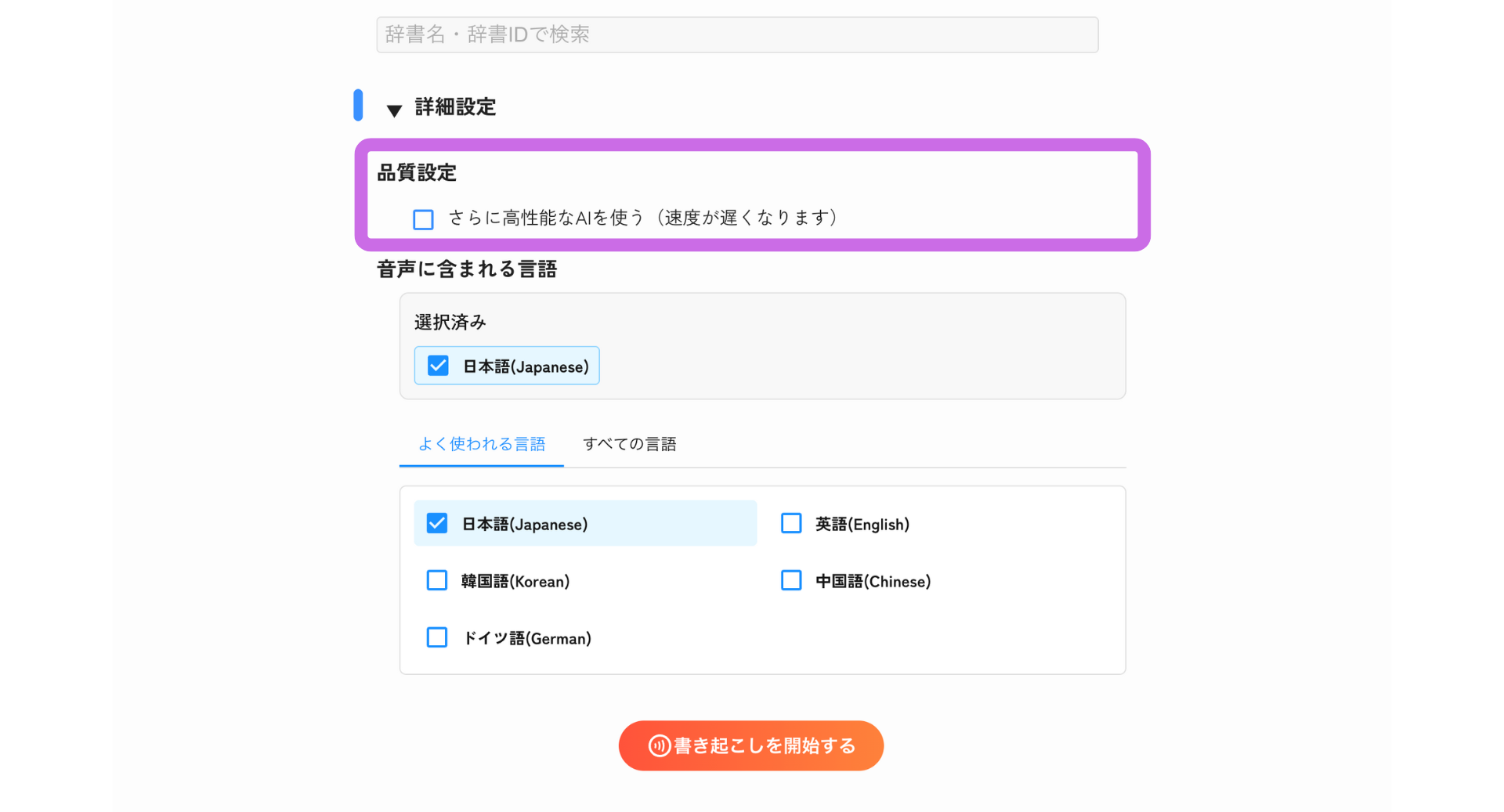
さらに高性能なAIを使う: このチェックボックスをオンにすると、より高精度なAIモデルを使用して書き起こしを行いますが、処理速度は通常より遅くなります。標準設定でも十分な精度が得られますが、より高い精度が必要な場合にご利用ください。
音声に含まれる言語
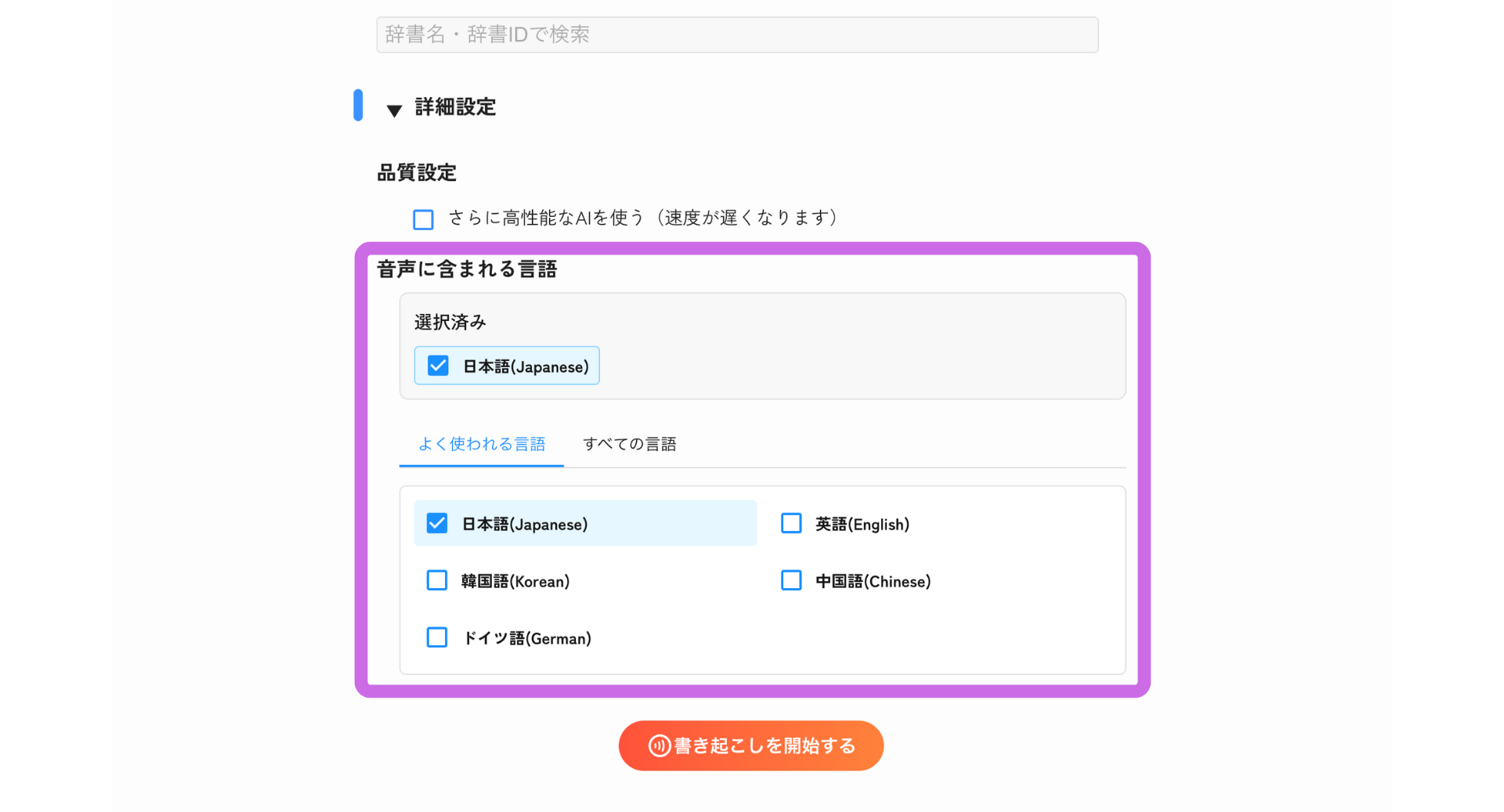
- 書き起こし対象の音声に含まれる言語を選択します。「よく使われる言語」タブから選択するか、「すべての言語」タブで他の言語を検索して選択できます。
- 複数の言語が混在する音声の場合は、該当する言語をすべてチェックしてください。(例: 日本語と英語が含まれる会議の場合は、「日本語(Japanese)」と「英語(English)」の両方にチェックを入れます)
- 選択した言語は上部の「選択済み」エリアに表示されます。
- 対応している言語の完全なリストは対応言語ページで確認できます。
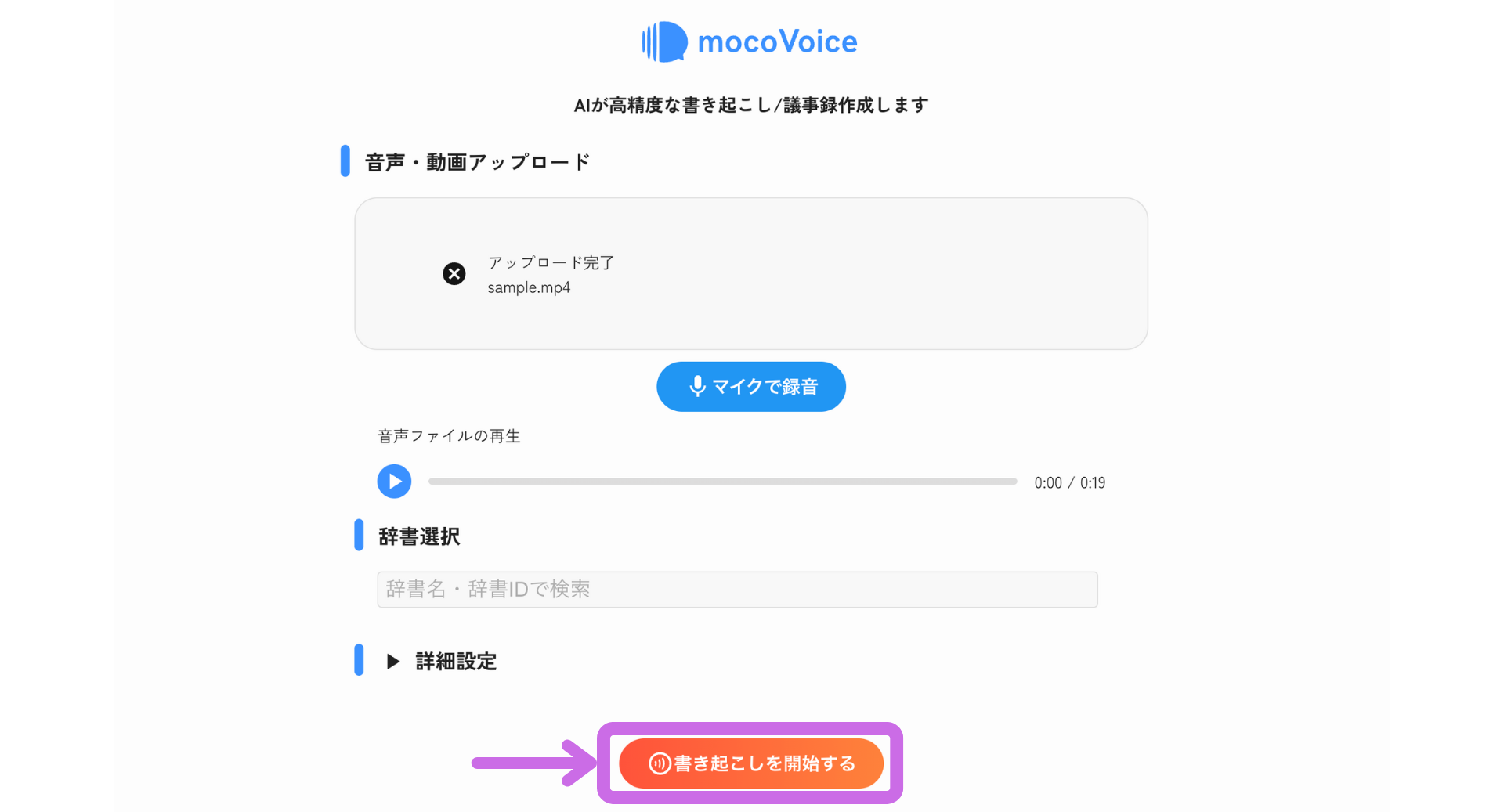
書き起こしの実行
音声入力(ファイルアップロードまたはマイク録音)とオプション設定が完了したら、「書き起こしを開始する」ボタンをクリックします。
アップロード処理中
ファイルのアップロードが開始されると、以下の画面が表示されます。アップロードには数秒〜数十秒かかることがあります。
アップロード中は画面を移動したり、ページを閉じたりしないようにしてください。

アップロードが完了すると、ファイル名が表示され、再生して内容を確認できるようになります。その後、オプション設定を行い、書き起こし処理に進みます。
書き起こし処理中
ボタンをクリックすると、書き起こし処理が開始されます。処理中は以下の画面が表示されます。音声の長さに応じて時間がかかりますが、このページを閉じてもバックグラウンドで処理は継続されます。処理状況は「書き起こし履歴」タブで確認できます。

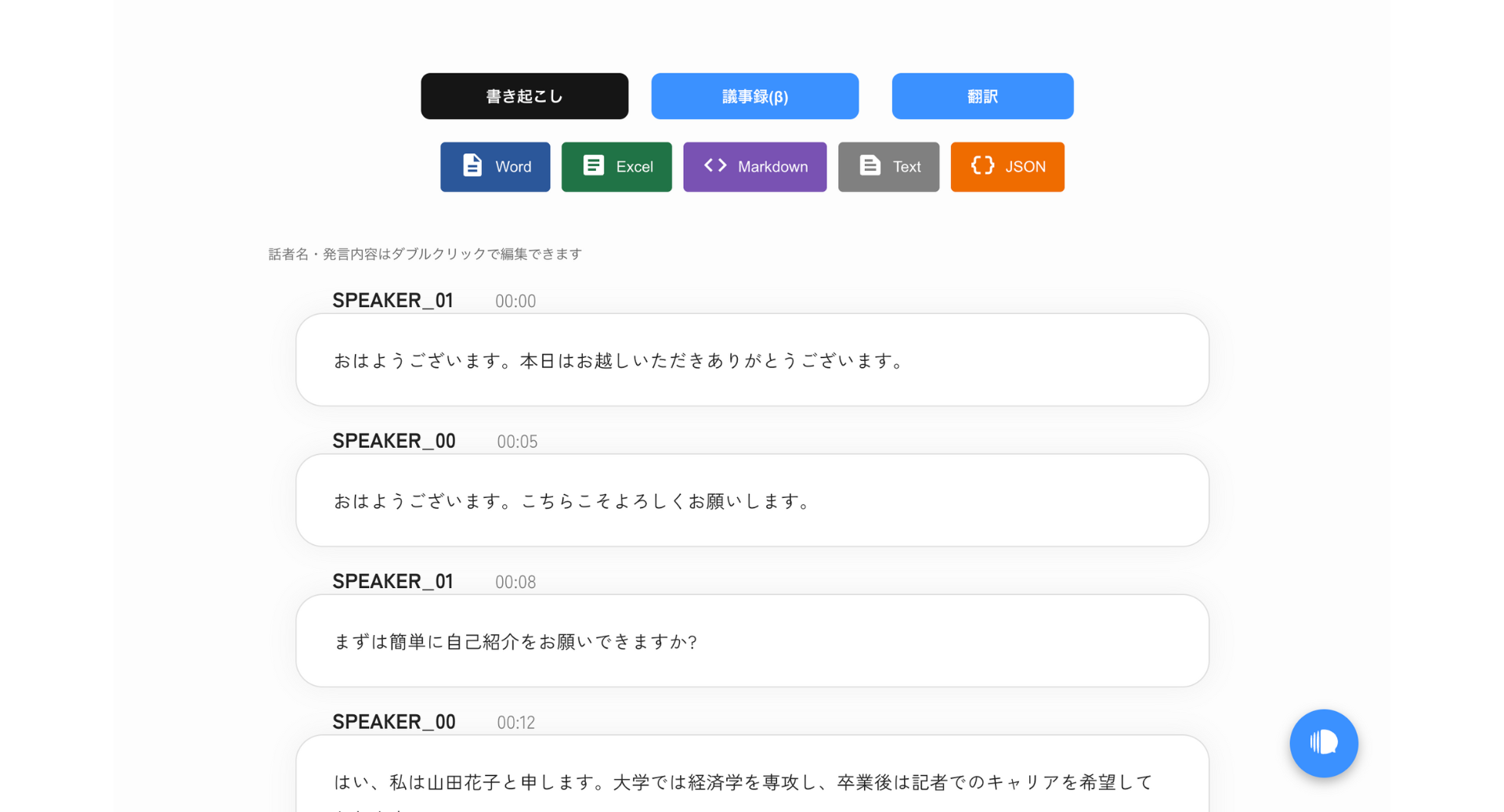
書き起こし結果の確認と整理
書き起こし処理が完了すると、自動的に結果表示画面に遷移します。
(ページを閉じていた場合は、「書き起こし履歴」から該当のジョブを選択してください)
画面には、話者ごとに分割された書き起こしテキストが表示されます。
3時間を超える音声ファイルの話者IDについて
mocoVoiceでは、3時間を超える長時間の音声ファイルも処理可能ですが、内部の話者分離処理は3時間単位で行われます。
そのため、3時間を境にして話者IDの割り当てが変わることがあります。具体的には、3時間以降に登場する話者には、それ以前と同じ人物であっても、新しい話者ID(例: SPEAKER_02, SPEAKER_03...)が割り当てられる場合があります。
例:
| 時間帯 | 話者ID | 実際の人物 |
|---|---|---|
| 0〜3時間 | SPEAKER_00 | Aさん |
| SPEAKER_01 | Bさん | |
| 3〜6時間 | SPEAKER_02 | (同じ)Aさん |
| SPEAKER_03 | (同じ)Bさん |
このように、3時間を超える区間では、同じ人物が再登場しても異なる話者IDが付与される可能性があります。
書き起こし結果を確認のうえ、必要に応じて同一人物に同じ名前を割り当てて整理してください。
👉 話者名を編集する
書き起こし結果から行える操作
書き起こし内容を確認した後、以下の操作が可能です。
結果のエクスポート
書き起こし結果は、以下の形式でダウンロードすることができます。
| 形式 | 拡張子 | 説明 |
|---|---|---|
| Word | .docx | 一般的な文書作成に適したMicrosoft Word形式です。 |
| Excel | .xlsx | タイムスタンプや話者情報が表形式で整理された形式です。 |
| Markdown | .md | プレーンテキストで軽量なマークアップ形式です。 |
| Text | .txt | シンプルなプレーンテキスト形式です。 |
| JSON | .json | 構造化データとして扱える形式で、プログラム処理に適しています。 |
話者名や結果の編集
話者IDが複数に分かれてしまった場合、同じ人物に対して同じ名前を割り当てることで、会話の流れを整理しやすくなります。
また、書き起こしの内容そのものを修正することも可能です。
議事録の作成
書き起こし結果から、会議やインタビューの議事録を作成できます。
👉 議事録を作成する
精度向上のための辞書利用
専門用語や固有名詞の認識精度を上げたい場合は、事前に辞書を登録・利用することで精度向上が期待できます。
👉 辞書を使って精度を上げる
上記の機能を組み合わせることで、書き起こし結果を効率的に整理・活用できます。